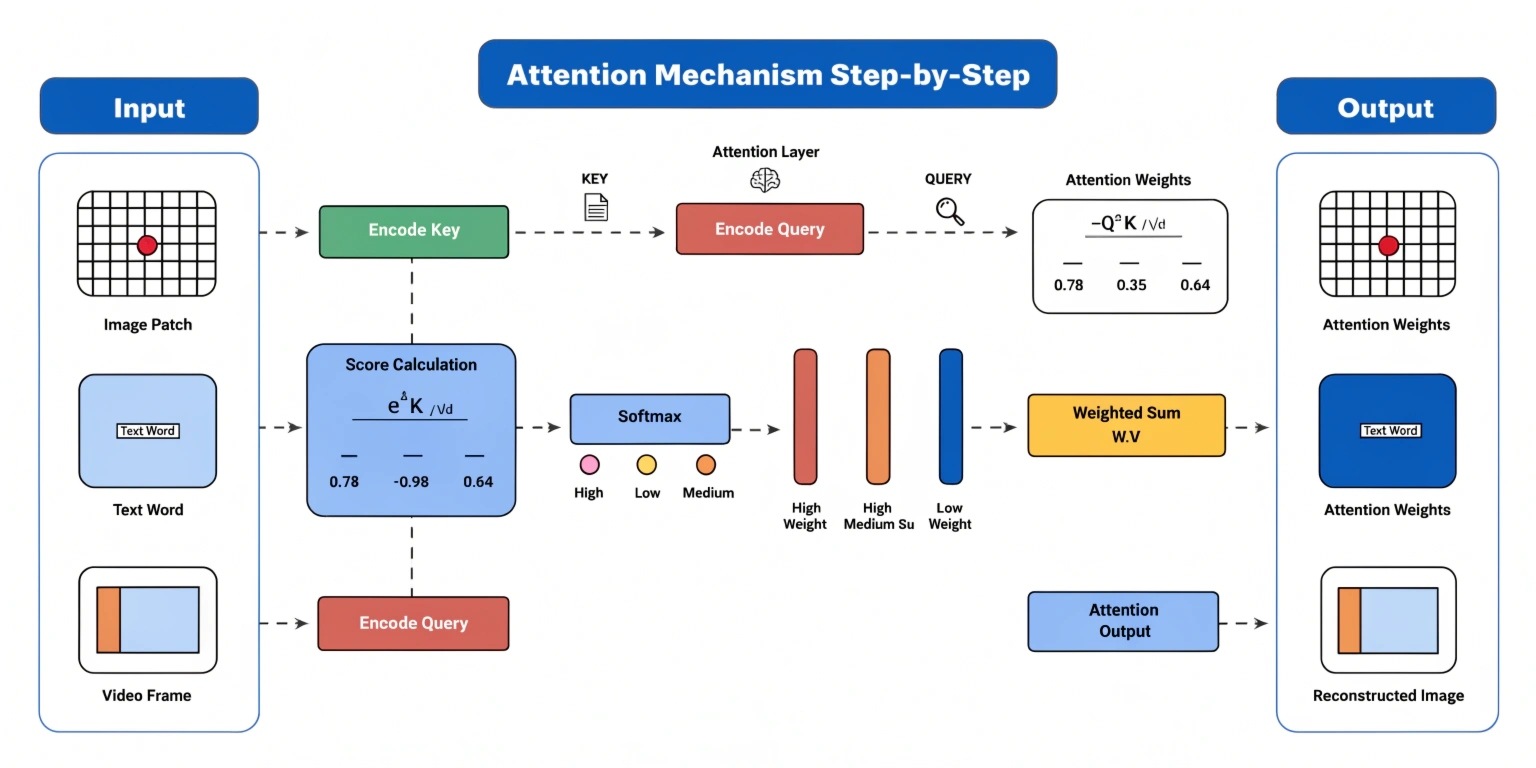
The attention mechanism is one of the most important breakthroughs in deep learning, especially in Natural Language Processing (NLP). It allows models to focus on the most relevant parts of input data instead of treating all information equally.
Let’s break it down step-by-step with real examples.
1. Why Attention Mechanism Was Needed
Before attention, models like Recurrent Neural Networks (RNNs) and LSTMs processed sequences step-by-step. The main problem was that they tried to compress all information into a single fixed-size vector.
Imagine translating a long sentence:“The food at the restaurant we visited yesterday was absolutely amazing.”
Traditional models struggled to remember earlier words like “food” when predicting later outputs.
This is where attention comes in.
2. What is Attention Mechanism?
Attention allows the model to look back at the entire input sequence and decide which words are important for predicting the current output.
In simple terms:
Instead of remembering everything equally, the model “pays attention” to important words.
3. Real-Life Example of Attention
Think of reading a sentence and answering a question:
Sentence:
"The cat sat on the mat because it was tired."
Question:
"Why did the cat sit?"
Your brain focuses on “because it was tired”, ignoring less relevant words.
This is exactly how attention works in AI models.
4. Step-by-Step Working of Attention
Let’s understand how attention works internally.
Step 1: Input Encoding
Each word in the sentence is converted into a vector (numerical representation).
Example:
- "The" → vector
- "cat" → vector
- "sat" → vector
Step 2: Query, Key, and Value Creation
For each word, three vectors are created:
- Query (Q) → What am I looking for?
- Key (K) → What do I contain?
- Value (V) → What information do I provide?
Step 3: Calculate Attention Scores
The model compares the Query with all Keys using a similarity function (dot product).
This tells us:
How important each word is relative to the current word.
Step 4: Apply Softmax
The scores are normalized using softmax to convert them into probabilities.
Example:
- Word1 → 0.1
- Word2 → 0.7
- Word3 → 0.2
This means Word2 is most important.
Step 5: Weighted Sum of Values
The final output is calculated by multiplying each Value vector with its attention weight.
This produces a context-aware representation.
5. Types of Attention
1. Self-Attention
Used in transformer models. Each word attends to every other word in the same sentence.
Example:
In “The bank of the river,” attention helps understand that “bank” refers to river, not finance.
2. Encoder-Decoder Attention
Used in translation models.
- Encoder processes input sentence
- Decoder uses attention to focus on relevant words while generating output
6. Attention in Transformers
The attention mechanism is the core of transformer models like GPT and BERT.
Key concept:
Transformers remove recurrence and rely entirely on attention.
This makes them:
- Faster
- More parallelizable
- Better at understanding long-range dependencies
7. Real-World Applications
1. Machine Translation
Google Translate uses attention to align words between languages.
2. Chatbots
Attention helps chatbots understand context better.
3. Text Summarization
Models focus on important sentences to generate summaries.
4. Speech Recognition
Attention helps map audio signals to words accurately.
8. Why Attention is Powerful
- Handles long sentences better
- Improves context understanding
- Reduces information loss
- Enables parallel processing
9. Simple Analogy to Remember
Think of attention like a highlighter pen:
Instead of reading everything equally, it highlights important parts.
Conclusion
The attention mechanism revolutionized deep learning by allowing models to focus on relevant information dynamically. From translation to chatbots, it powers some of the most advanced AI systems today.
Understanding attention is essential if you want to master modern AI concepts like transformers, GPT, and BERT.

