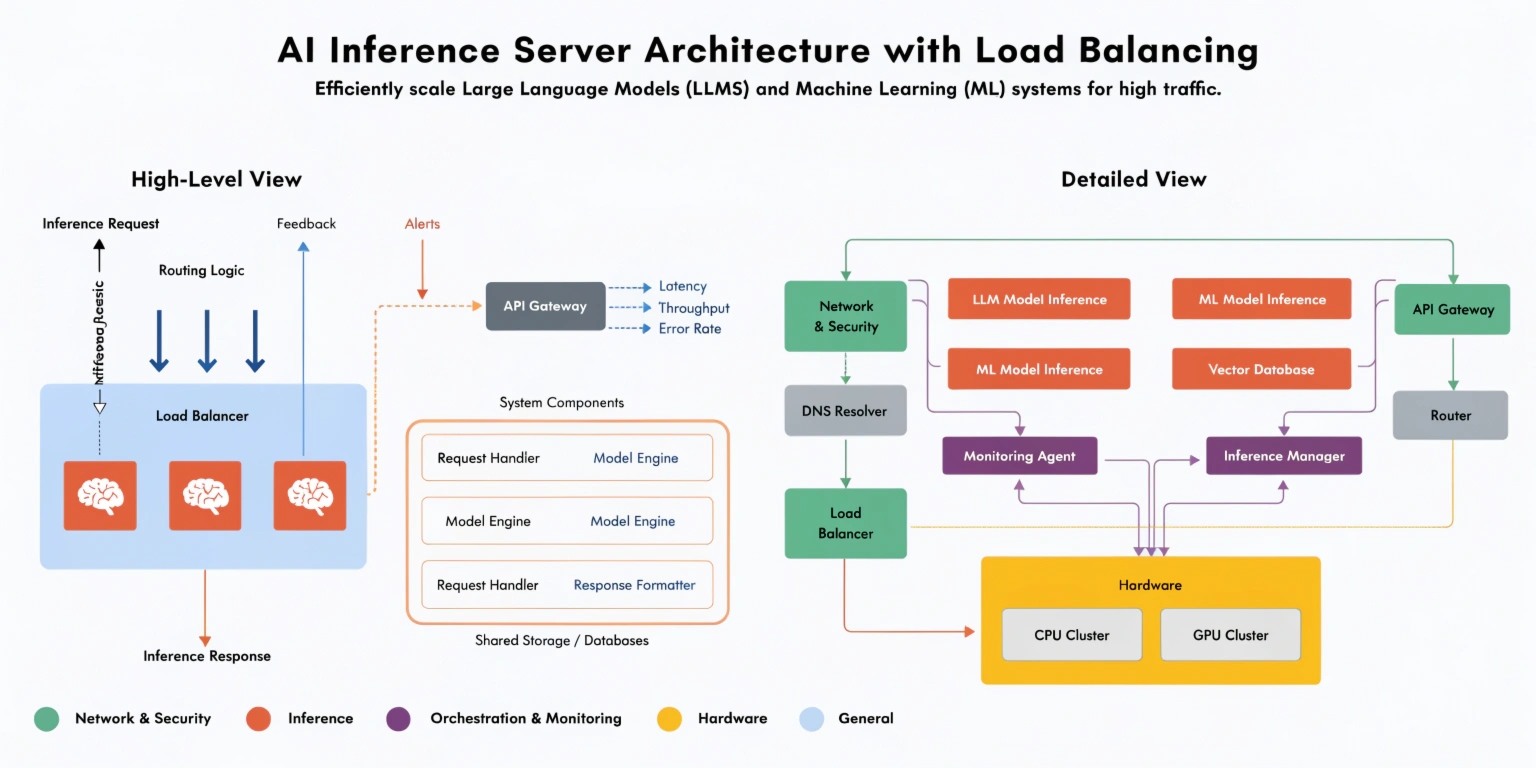
As AI applications move from prototypes to production, one challenge becomes unavoidable: scaling inference.
When a machine learning or Large Language Model (LLM) application starts receiving thousands of requests per minute, a single server cannot handle the load. Without proper load balancing, systems crash, latency increases, GPU resources get exhausted, and users experience failures.
Load balancing in AI inference servers is the backbone of scalable, production-ready AI systems.
Let’s explore how it works and why it is critical.
1. What Is an AI Inference Server?
An inference server is responsible for running a trained model and returning predictions.
Examples:
- Text generation from an LLM
- Image classification
- Fraud detection predictions
- Recommendation engine outputs
Frameworks like NVIDIA Triton Inference Server and TorchServe are commonly used to deploy models in production.
Unlike training, inference must be:
- Low latency
- Highly available
- Scalable
- Cost efficient
This is where load balancing becomes essential.
2. Why Load Balancing Is Critical for AI
AI inference is resource-intensive. Especially with LLMs running on GPUs, each request consumes memory, compute cycles, and bandwidth.
Without load balancing:
- One GPU gets overloaded
- Response time increases
- Requests start timing out
- System becomes unstable
With proper load balancing:
- Traffic is distributed evenly
- No single server becomes a bottleneck
- System remains responsive under heavy load
For AI products serving SaaS users, this directly impacts revenue and user trust.
3. Horizontal vs Vertical Scaling
There are two main approaches to scaling inference servers:
Vertical Scaling
Increasing the power of a single machine.
Example:
- Moving from 1 GPU to 4 GPUs
- Upgrading CPU and RAM
This works temporarily but is limited and expensive.
Horizontal Scaling
Adding more servers to distribute load.
Example:
- 1 inference server → 10 inference servers
- Traffic distributed via load balancer
Modern AI systems rely heavily on horizontal scaling.
4. Load Balancing Strategies in AI Systems
Different traffic routing strategies are used depending on the use case:
Round Robin
Each request goes to the next server in sequence.
Simple but doesn’t account for server load.
Least Connections
Traffic goes to the server with the fewest active requests.
Better for uneven workloads.
Resource-Based Routing
Traffic is routed based on:
- GPU utilization
- Memory usage
- Response latency
This is ideal for AI inference systems where GPU memory varies per request.
5. Kubernetes and AI Load Balancing
Most enterprise AI systems are deployed using Kubernetes.
Kubernetes helps with:
- Automatic load balancing
- Pod autoscaling
- Health checks
- Rolling updates
- Fault tolerance
When inference traffic increases:
- Kubernetes automatically spins up new pods
- Traffic is redistributed
- System maintains performance
This process is known as Horizontal Pod Autoscaling (HPA).
For AI systems, autoscaling can be triggered by:
- CPU usage
- GPU utilization
- Request queue length
- Custom metrics
6. GPU Load Balancing Challenges
AI inference introduces a unique challenge: GPUs are not like CPUs.
GPU memory can fill up quickly with:
- Large model weights
- Long context windows
- Multiple concurrent requests
Solutions include:
Model Sharding
Splitting model layers across multiple GPUs.
Request Batching
Combining multiple inference requests into one batch to improve throughput.
Multi-Model Serving
Hosting different models on separate GPU pools to prevent interference.
Frameworks like Ray Serve help manage distributed inference efficiently.
7. API Gateway Layer
Before traffic reaches inference servers, it typically passes through:
- API Gateway
- Reverse Proxy
- Rate Limiter
Tools like NGINX or cloud load balancers distribute incoming requests.
This layer handles:
- Authentication
- Rate limiting
- SSL termination
- Traffic routing
This prevents malicious or excessive traffic from overwhelming AI servers.
8. High Availability and Fault Tolerance
Production AI systems must survive failures.
Best practices:
- Deploy across multiple availability zones
- Use health checks to remove unhealthy nodes
- Implement circuit breakers
- Maintain fallback models
If one inference node fails:
- Load balancer reroutes traffic
- No downtime is experienced by users
This is critical for:
- FinTech AI systems
- Healthcare AI
- Real-time analytics platforms
9. Reducing Latency in Distributed AI Systems
Load balancing also impacts latency.
Techniques to optimize performance:
- Geo-distributed inference servers
- Edge inference for regional users
- Response streaming
- Smart caching of repeated queries
For LLM applications, caching repeated prompts can reduce cost and latency significantly.
10. Cost Optimization in AI Scaling
More servers mean higher costs.
Smart load balancing helps:
- Prevent idle GPU time
- Scale down during low traffic
- Route simple tasks to smaller models
- Use serverless inference when possible
Balancing performance and cost is the real engineering challenge.
Conclusion
Load balancing in AI inference servers is not just about distributing traffic — it is about designing intelligent, resilient, and cost-effective AI infrastructure.
As AI adoption increases, companies must move beyond single-server deployments and adopt distributed, autoscaling architectures.
The future of AI systems lies in:
- Distributed GPU clusters
- Kubernetes-based orchestration
- Intelligent traffic routing
- Real-time monitoring
If your AI system cannot handle traffic spikes, it is not production-ready.
Scalability is not optional in modern AI — it is foundational.

